
From “Models for Ensemble Statistical Doubt” to “Markets for Individual Clinical Ambiguity”

Rodolfo LLinás’ theory of the brain, as an emulator of reality that coordinates motion through predictions, suggests fundamental limits pointing to shorter rather than longer-term predictions. See prior post:

Herbert Weisberg wonders about the statistical validity of ensemble-level predictions, given the implicit or explicit level of willful ignorance to individual differences that comes from averaging processes. See source below:
- Source: Weisberg, Herbert I. (2014), Willful Ignorance, The Mismeasure of Uncertainty, Wiley
Given these structural limits in time and scale, what makes predictions valuable for individual decision-making?
- In Llinás’ case, the value of a prediction comes from feedback about the precision and accuracy of an individual physical motion:
o The self takes responsibility for its actions and predictions.
- In Weisberg’s case, it comes from its focus on clinical ambiguity at the individual level instead of statistical doubt at the group level, and to paraphrase:
o “Is applying group averages to individuals the best that we can do, or are we doing this in the hope of avoiding the burden of responsibility for personal judgment?”
Weisberg’s comment extends Carlo Cipolla’s observations about the Large World quadrants, see chart below as well as prior posts for details, where mathematical methods – instead of heuristics - can cause damage to individuals by using:
- The wrong type of averages (e.g. ensemble vs. time average) as shown by ergodicity economics, and explained in a prior post about Rory Sutherland presentation at the EE2022 Conference,
- Mathematical methods on data that does not meet their constraining assumptions as documented in a prior post about the Constrained Task Environments of the Logic & Statistics program, and
- Academically interesting, but not practically useful, loss functions and measures of outcomes as presented in the rest of this post.
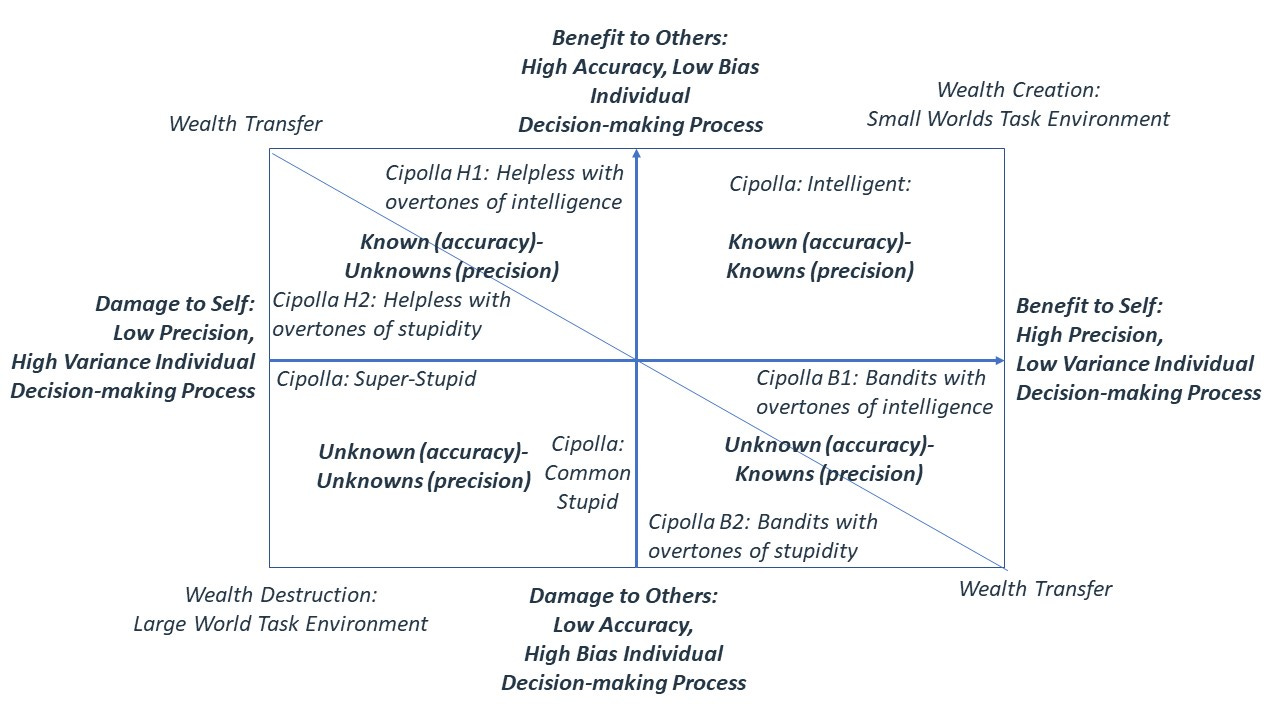
Further, the chart shows that individuals that insist on using such mathematics methods in the wrong task environments can not only hurt themselves but also hurt others.
Machine Prediction for Investment Management
Machine learning, like individual people, must match methods to task environments in order to avoid outcomes that fall in the bad quadrants of Cipolla’s chart.
The gist of machine learning is prediction or classification from in-sample knowledge to out-of-sample ignorance, using mathematical methods such as probabilities, that are subject to constraining assumptions about their valid, data task environment.
Wojtek Buczynski, and his co-authors suggest that machine-driven predictions have yet to demonstrate practical value in the task environments of investment management, see source below:
- Source: Buczynski, Wojtek, Cuzzolin, Fabio, Sahakian, Barbara (2021), A review of machine learning experiments in equity investment decisio-making: why most published research findings do not live up to their promise in real life, International Journal of Data Science and Analytics (2021) 11:221-242
Their paper analyzes 27 peer-reviewed articles selected as follows:
- Empirical, first-hand experiments in AI forecasting of financial markets in general and equity markets in particular,
- Published in a peer-reviewed journal in the last 25 years (1994-2019), and
- Focused on long-term (month/year/indefinite) investing horizons.
Rejected articles focused on:
- Other asset classes such as fixed income,
- Millisecond to hours forecast horizons, or
- Computational aspects instead of investment value.
Their paper shows that the studies in the selected articles suffer from many challenges for practical implementation, including:
- “Back-test overfitting”, denoting a situation where “… a model targets particular observations rather than a general structure.”,
- “Cherry-picking”, using more than one model in testing, thus impractical from a “…. real life investment perspective.”,
- “Mean-based” error metrics that disregard temporal effect and discounting, thus missing the real-life impact of outliers on chain-linked, compounded investment results, and
- “Black-boxes” that cannot explain their results, thus likely to raise regulatory or legal concerns.
Further, their review documents a cognitive dissonance between academic claims of accurate predictions, and observable investment industry outcomes.
Their paper closes with several recommendations that include:
- using full disclosure of forecast time series to “ … reveal divergence from actual equity index time series, all the outliers, dispersion of forecast values, etc.”
Machine Classification for Investment Management
Gautier Marti, et al. reviewed the state-of-the-art of “clustering financial series” (classification of correlations), and found challenges that keep results remote from becoming part of the standard toolbox of financial practitioners.
Source: Marti, Gautier, Nielsen, Frank, Binkowski, Mikolaj, Donnat, Philippe (2020), arXiv:1703.00485v7 [q-fin.ST] 3 Nov 2020
The potential mismatches between data and the constraining assumptions of mathematical methods, presented in an earlier post, shows up as a top concern of the authors:
- [Academic studies] “… employed techniques that rely on finite variances and stationary processes when there is considerable doubt about the existence of these conditions” [in the data that is based on historical stock returns]
This paper goes on to document a large number of academic alternatives for:
- Algorithms that would replace the minimum spanning tree (MST),
- Measures of distances other than expected squared deviations,
- Statistical processing for improved reliability and treatment of uncertainty, and
- Use of alternative data beyond price series.
In the end, the paper concludes that:
- the value for the task environments of investment management continues to appear more academic than practical, and
- many challenges need to be overcome before these techniques can become part of the partitioner’s toolbox.
The Murmurations of Micro-Predictions
Looking for machine learning methods that would display transparency, and offer practicality in the task environments of investment management led to reading about Peter Cotton’s work on micro-predictions.
- Source: Cotton, Peter (2019), Self Organizing Supply Chains for Micro-Prediction: Present and Future uses of the ROAR Protocol, arXiv:1907.07514.v1 [stat,AP] 17 Jul 2019
Cotton sees Artificial Intelligence ” … as a series of predictions”, and his work addresses many of the issues highlighted in Buczynski’s and in Marti’s papers, including:
- Algorithm transparency,
- Process transparency,
- Temporal considerations, and
- Practical success metrics.
The paper traces its roots to Applied Statistics, and the crowd-sourcing of knowledge development with Data Science contests that use standardized datasets.
Cotton summarized his improvements to the existing quantitative contest communities with the Repeated Online Analytical Response (ROAR) protocol, a platform for streaming prediction contests that gathers:
- Buyers of prediction precision & accuracy that provide streaming data, with scheduled updates on business topics that include Financial markets, Weather observations, Energy consumption, and Traffic patterns,
- Sellers of prediction precision & accuracy that deploy prediction models and matching algorithms,
- A back-end clearinghouse that tracks algorithm performance and settles rewards/prices based on prediction precision & accuracy,
- A front-end interface for buyers to post data streams, and receive predictions, and
- A front-end interface for sellers to deploy algorithms and to track results on a “leaderboard”.
Cotton’s work brought back to mind old memories of flocking algorithms:
- Rational Investors (a dot.com robo-advisor sold to S&P in 1999) started in 1995 as an idea called “Chicken Brains”, based on a vision of small flocking algorithms attached to each individual investment asset,
- With the hope of creating observable and valuable “murmurations” at the portfolio level (note: when European starlings flock at certain times of year, they create large scale patterns in the sky called murmurations.), however,
- Technological constraints, and the emergence of the World Wide Web turned “Chicken Brains” into “Rational Investors, Inc.” with the development of Java-based applets to provide “mass-customized investment management in 401(k) plans over the Internet”.
As a follow-up to his paper, Peter Cotton created a public website, with a matching platform for algorithmic murmurations:
https://www.microprediction.com/
To quote from the website:
- When you post numbers over time to the platform [as a buyer of prediction precision & accuracy], “… you automatically lure reward-seeking forecasting algorithms that monitor streams and make short-term distributional predictions of future data values you are yet to publish.”
Interestingly, his approach may provide:
- empirical answers to the question of applying mathematical methods with constraining assumptions on data that does not meet those assumptions, and
- A market-place for testing competing algorithms from the Logic & Statistics program as well as the Heuristics program.
Future posts will document personal experience at running algorithms [as a seller of prediction precision & accuracy] on Peter Cotton’s micro-prediction platform.
“CTRI by Francois Gadenne” connects the dots of life-enhancing practices for the next generation, free of controlling algorithms, based on the lifetime experience of a retirement age entrepreneur, and as the co-founder of CTRI continuously updated with insights from Wealth, Health, and Statistics research performed on behalf of large companies.